어떤 상황에 쓰는가

- 파드를 만들면, 컨테이너가 생기고, 파드와 컨테이너 상태가 Running이 되고 앱도 구동이 됨
- 서비스와 파드가 연결이 되고, 서비스의 아이피가 외부에 알려지고, 외부에서 사람들이 서비스를 통해 접근
- 한 서비스에 2개의 파드가 연결되어 있으니 50%씩 트래픽이 나눠진다고 하자
ReadinessProbe를 사용하는 상황

- 갑자기 노드2가 다운되고 그 위에 파드2도 다운됨
- 사람들은 남은 하나의 노드에만 접속을 하게됨
- 죽은 파드2는 Auto Healing 기능을 통해 다른 노드3 위에 재생성 되려고 함
- 파드2와 컨테이너가 Running이 되어 서비스와 연결되지만 앱이 Booting 중인 상황이 발생
- 이 때, 트래픽이 파드2로 오게되면 사용자는 에러페이지를 보게 됨
- 이 때, ReadinessProbe를 주면 문제 해결
- ReadinessProbe는 앱이 구동되기 전까지 서비스와 연결이 되지 않도록 해줌
- 앱이 완전히 준비된게 확인되면 서비스와 연결되고, 트래픽은 50%, 50%씩 흐르게 됨
LivenessProbe 사용하는 상황

- 위 상황에 이어서 파드2의 앱이 장애가 남, 근데 파드2는 돌아감(500 Internal Server Error)
- 이 때, 앱의 장애상황을 감지하는게 LivenessProbe
- LivenessProbe: 앱에 문제가 생기면 해당 파드를 다시 실행함
ReadinessProbe, LivenessProbe 설정 내용

- httpGet, Exec, tcpSocket은 ReadinessProbe, LivenessProbe에서 공통으로 설정하는 내용
- httpGet: 포트, 호스트이름, Path, HttpHeader, Schme 확인 가능
- Exec: 특정 명령어를 날려서 결과 확인
- tcpSocket: 포트번호와 호스트명을 확인해서 ReadinessProbe, LivenessProbe에 대한 성공여부 확인
- 셋 중 하나는 꼭 정의해야 함
세부 옵션
- initialDelaySeconds: 최초 Probe하기 전 delay 설정
- periodSeconds: Probe를 확인하는 시간의 간격
- timeoutSeconds: 지정된 시간까지 결과가 와야함
- successThreshold: 몇 번의 성공 결과를 받아야 정말 성공으로 인정할건지
- failureThreshold: 몇 번의 실패 결과를 받아야 정말 실패로 인정할건지
- 각 설정값을 넣지 않으면 그림의 값이 default
ReadinessProbe
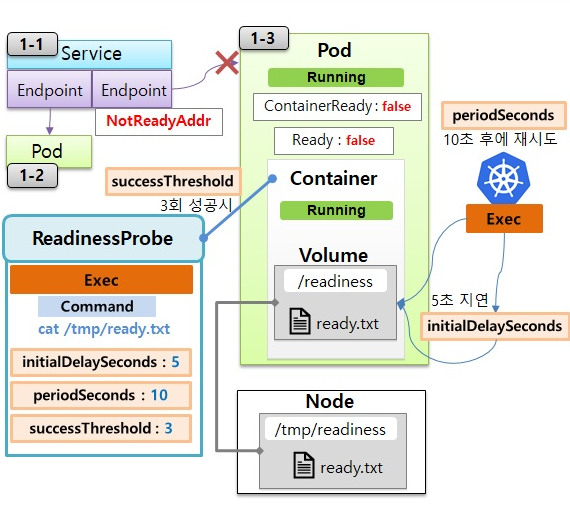
- 서비스에 파드가 연결되어 있음
- 이 때, 파드를 하나 더 만들려고 하는데, 그 파드의 컨테이너의 hostPath로 노드의 Volume이 연결되어 있음
컨테이너에 ReadinessProbe를 설정
- Exec를 사용해서 command로 readiness/ready.txt를 조회
- 옵션으로 최초 딜레이는 5초, 확인 간격은 10초, 3 번의 조회를 성공해야 정상적으로 구동했다고 간주
- 이 옵션을 바탕으로 파드를 만들 때, 노드가 스캐줄 되고 이미지가 다운받아지면서 파드와 컨테이너는 Running이 됨
- Probe가 성공하기 전까지 Condition의 ContainerReady, Ready는 false로 유지
- 파드의 컨디션이 ContainerReady: false, Ready: false로 지속되면 서비스의 Endpoint에서 파드의 ip를 NotReadyAddr로 간주하고 서비스에 연결하지 않음
쿠버네티스의 ReadinessProbe 설정 확인
- 쿠버네티스는 ReadinessProbe에 정의된 내용으로 앱 서비스의 기동상태를 확인
- 컨테이너 상태가 Running이 되면 최초 5초 지연 후 ready.txt가 있는지 확인 --> initialDelaySeconds: 5
- 파일이 없으면 10초 후에 다시 확인 --> periodSeconds: 10
- 계속 데이터가 없으면 파드의 컨디션은 false로 유지됨
- 이 때, Node에 ready.txt가 추가되면, 컨테이너의 Volume과 연결되어 있어서 다음 ReadinessProbe는 성공
- 성공을 3번 받게 되면 컨디션의 상태는 true가 됨 --> successThreshold: 3
- 컨디션의 상태가 true가 되면, 서비스의 Endpoint도 address를 정상으로 간주하고 파드와 서비스가 연결됨
LivenessProbe
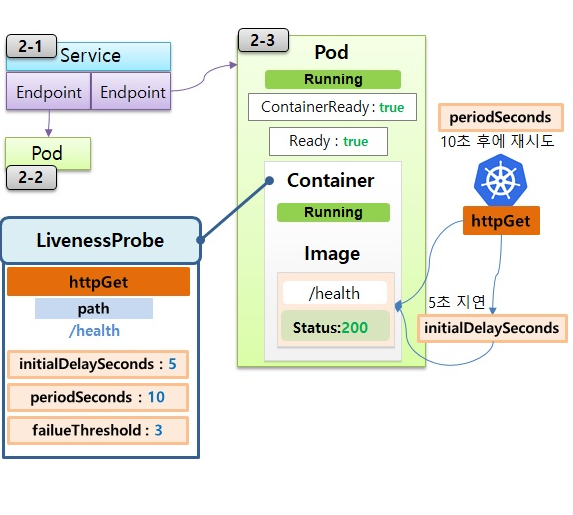
- 한 서비스에 두 파드가 Running 상태
- 컨테이너에는 앱이 있고, 이 앱에 /health를 날리면 Status:200을 받고, 서비스가 정상적으로 운영중임을 알려줌
컨테이너에 LivenessProbe 설정
- httpGet으로 path에 /health 경로를 확인
- 옵션으로 최초 딜레이는 5초, 확인 간격은 10초, 3번의 조회를 실패하면 실패라고 간주
쿠버네티스의 LivenessProbe 설정 확인
- 쿠버네티스가 httpGet으로 5초 후에 path를 확인하고 200 ok를 받음 --> initialDelaySeconds: 5
- 10초 후에 또 확인하고 200 ok 받으면서 서비스가 정상적으로 운용 중이라고 판단 --> periodSeconds: 10
- 근데 어느 순간부터 path를 호출하면 Internal Server Error 500을 받음
- Internal Server Error 500을 3회 받게 되면 쿠버네티스는 앱에 문제가 있다고 판단하고 파드를 Restart함 --> failureThreshold: 3
출처
인프런 - 대세는 쿠버네티스
'네트워크 > k8s' 카테고리의 다른 글
| [k8s] 21. Pod - QoS Classes (0) | 2021.02.17 |
|---|---|
| [k8s] 20. Pod - ReadinessProbe, LivenessProbe - 실습 (0) | 2021.02.17 |
| [k8s] 18. Pod - Lifecycle (0) | 2021.02.16 |
| [k8s] 17. DaemonSet, Job, CronJob - 실습 (0) | 2021.02.14 |
| [k8s] 16. DaemonSet, Job, CronJob (0) | 2021.02.14 |



